Canelle Maitre
What do you see?

01
Le sujet
Dans le cadre d’un workshop intitulé Sémiotique des interfaces, j’ai dû réaliser une expérimentation sur le thème de l’Eau. Dans un premier temps, j’ai listé ce à quoi me faisait penser ce mot. Je me suis alors retrouvé avec des mots comme : bleu, mer, calme. Puis, j’ai regardé ce qui m’entourait et j’ai vu sur mon bureau une tâche laissée par ma tasse de thé. Cette tâche avait une drôle de forme, cela m’a fait penser au test de Rorschach je me suis alors demandé comment les autres pouvaient interpréter cette forme, mais surtout comment une Intelligence Artificielle pouvait le faire.
J’ai lu plusieurs articles pour en apprendre un peu plus sur le test de Rorschach et j’ai découvert que des scientifiques avaient déjà fait passer ce test à l’intelligence artificielle de Google et les résultats étaient étonnants.
Avec cette expérience, je voulais tester plusieurs paramètres comme la couleur et l’orientation afin d’essayer de comprendre sur quoi se base l’IA pour apporter une réponse.

02
L'expérience
Le protocole
Pour commencer l’expérience, j’ai découpé et aligné des morceaux de papier qui me serviront de support. Ensuite, j’ai commencé à faire des tâches en utilisant un pinceau ou en versant directement des gouttes d’eau colorée et d’encre. J’ai finalement plié ces bouts de papier en deux afin de recréer cet effet de symétrie qu’on retrouve dans le test de Rorschach.
Le matériel
- Papier Canson
- Eau
- Pinceau
- Encre bleue
- Colorants alimentaires
- Sachet de thé
- Scanner
- Adobe Photoshop
- Google Vision API

Lorsque j’ai réuni ces échantillons de tâches, je me suis rendue compte que les morceaux de papier étaient assez étroits et que cela empêchait l’encre de s’étendre. Je cherchais à obtenir des formes plus complexes afin de mettre à l’épreuve l’IA. Ainsi, j’ai décidé de faire d’autres tests en utilisant de l’encre bleu sur un support plus grand. J’ai enfin réussi à obtenir une tâche qui me convenait.
Après cela, j’ai scanné cette tâche puis je l’ai modifiée en utilisant le logiciel Photoshop afin d’en changer la couleur et l’orientation. Je me suis alors retrouvée avec plusieurs photos que j’ai présentées à Googler Vision.



03
Les résultats
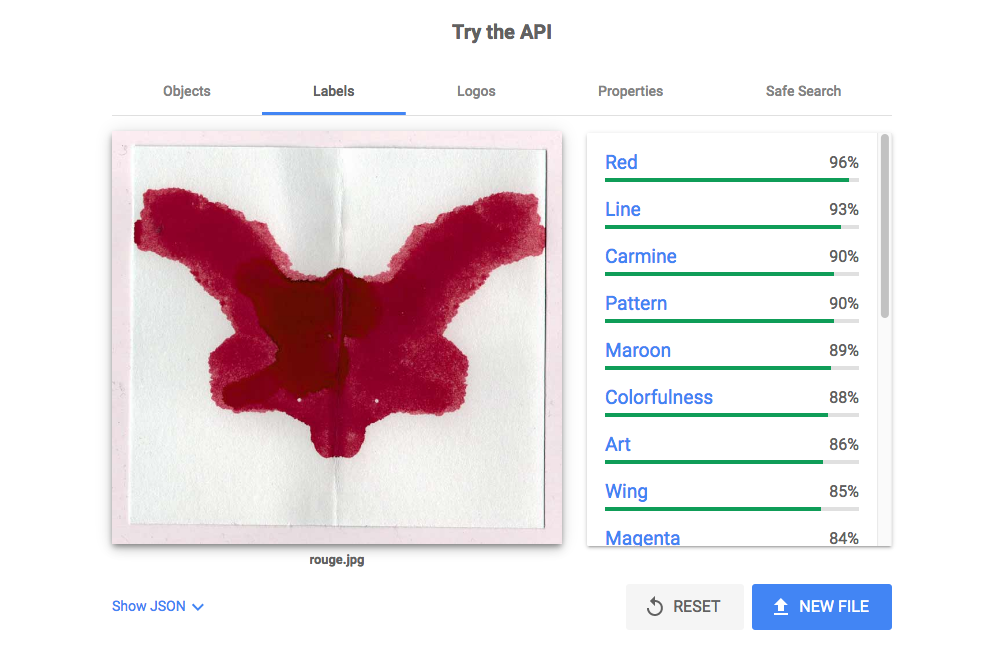
Voici les résultats obtenus lorsque j’ai entré les images dans l’outils de Google Vision.
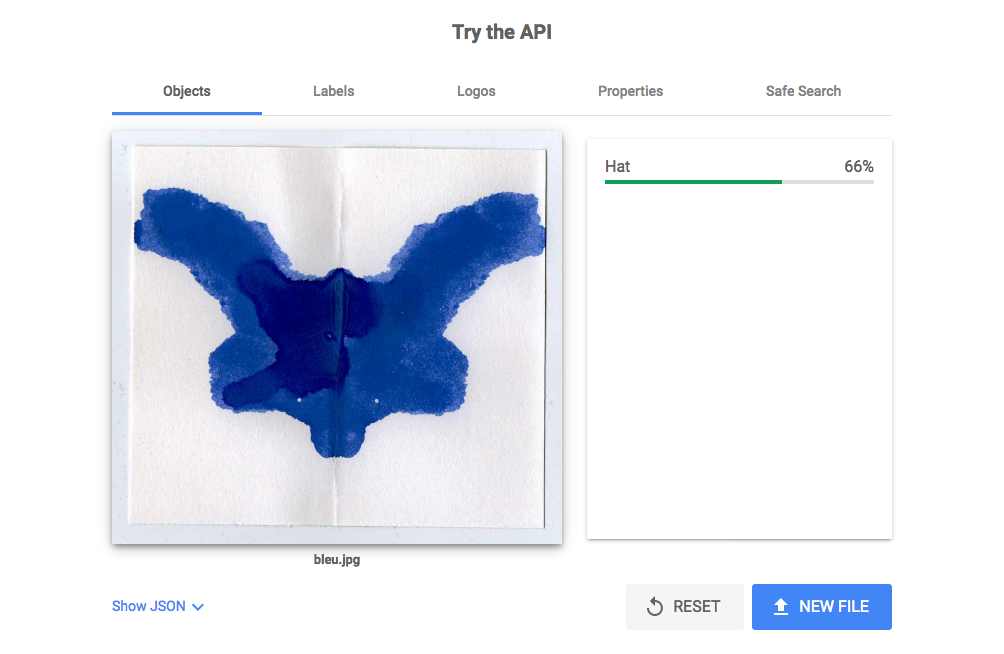
Ce qui m’a surpris dans un premier temps est le fait que l'IA trouve une correspondance assez rapidement. On aurait pu s’attendre, puisqu’il s’agit de formes abstraites, qu’elle ne trouve pas de correspondance.
Ensuite, j’ai observé que l’IA me proposait le même résultat quelque soit la couleur et l’orientation de la tâche. En effet, lorsqu’il s’agit de chercher un objet, le résultat est un chapeau.
Cependant, Google Vision nous propose plusieurs catégories de réponses. On se retrouve alors pour la catégorie Logo avec un brocoli pour la tâche verte, le logo Lego pour la tâche bleue et enfin un produit de consommation pour la tâche rouge. Puisque changer ce paramètre a un impact sur le résultat obtenu, on peut en conclure que la couleur affecte l’interprétation de l’image.
Finalement, je me suis penchée sur les étiquettes que l’IA avait attribuées aux images. Les catégories proposées allaient dans le sens de notre hypothèse précédente car on retrouve pour chaque tâche des mots comme “Feuille” pour la tâche verte et “Coquelicot” pour la tâche rouge. Ensuite, et c’est ce qui m’a le plus étonnée, l’outil nous propose les étiquettes “Dessin”, “Peinture” et “Illustration”. On peut alors se dire que l’IA a reconnu qu’il s’agissait bien d’une tâche et non de la photo d’un objet réel.
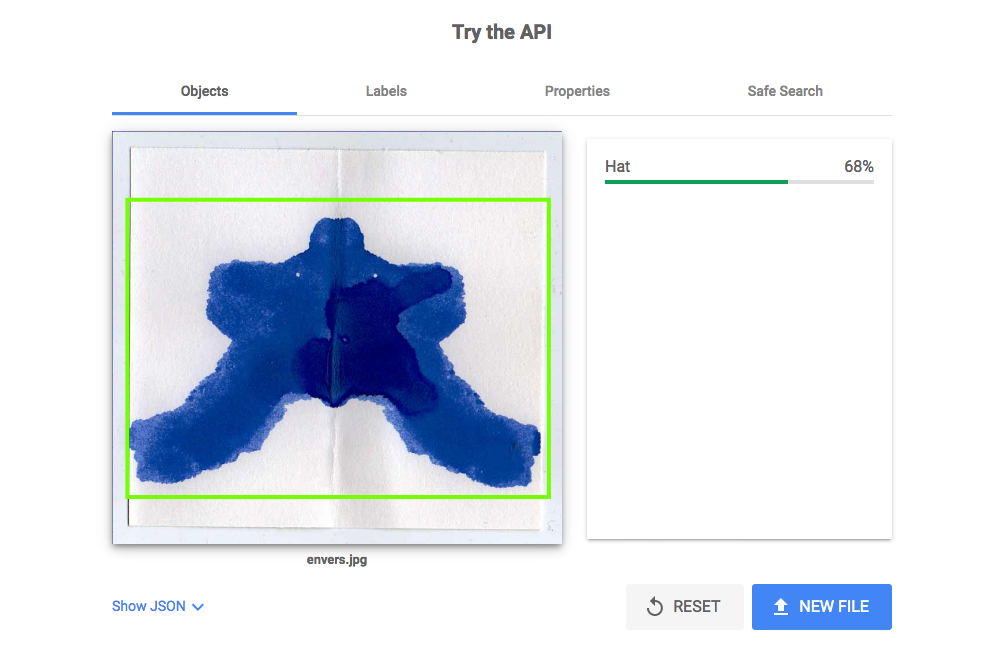
Questionnements
Tous ces résultats mènent à plus de questionnement. En effet, la psychologie et la sémiotique nous ont appris qu’entre autres l’humain se base sur des concepts comme ceux de gestalt et sur son expérience des signes et des sens qu’il leur attribue. On peut alors se demander si le fonctionnement est le même pour les intelligence artificielle.
De plus, on sait que l’IA de Google est alimentée et “instruite” par de nombreux utilisateurs notamment par les Captcha (qu’il faut d’ailleurs cocher avant de pouvoir envoyer une image sur Google Vision). On peut donc se questionner sur le résultat que nous propose l’outil, s’il est le fruit de sa propre expérience et si cette expérience ne serait pas en réalité un assemblage de l’expérience de tous les utilisateurs de Google. S’ajoute à cela la question de subjectivité appliquée aux algorithmes. Pour certains, rien n’est objectif et donc tout a une part de subjectivité y compris les algorithmes car ils sont écrits par un être humain. Ainsi, on peut se demander si les résultats trouvés par l’IA de Google sont purement objectifs.
Pour aller plus loin, on pourrait se demander quels seraient les résultats si ce n’était pas une image qui était présentée à l’IA mais bien le bout de papier directement ou alors si les résultats seraient différents avec une autre AI que celle de Google.
Chez les humains
Pour m’amuser, j’ai décidé de demander à mes amis comment ils interprétaient ces tâches. Le résultat est amusant car les réponses correspondent totalement à la personnalité de la personne interrogée. Par exemple, j’ai eu le droit à un bassin humain de la part d’une personne faisant des études dans le sport et la physiologie et une autre passionnée de musique m’a dit que cela lui faisait penser au clip de Gnarls Barkley “Crazy”. Pour ma part je vois plutôt un lapin avec des yeux et de grandes oreilles !

Sources
SEARLS, D. (2019) “How does the Rorschach inkblot test work?” https://www.youtube.com/watch?v=LYi19-Vx6go
PALMER, S E. (1999) "Les théories contemporaines de la perception de Gestalt" https://www.persee.fr/doc/intel_0769-4113_1999_num_28_1_1773